监督学习三要素
模型和参数
模型指给定输入 Xi 如何去预测 输出 Yi。 我们比较常见的模型如线性模型(包括线性回归和 logistic regression)采用了线性叠加的方式进行预测 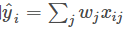 。这里的预测 y 可以有不同的解释,比如我们可以用它来作为回归目标的输出,或者进行 sigmoid 变换得到概率,或者作为排序的指标等。而一个线性模型根据 y 的解释不同(以及设计对应的目标函数)用到回归,分类或排序等场景。 参数指我们需要学习的东西,在线性模型中,参数指我们的线性系数 w。
。这里的预测 y 可以有不同的解释,比如我们可以用它来作为回归目标的输出,或者进行 sigmoid 变换得到概率,或者作为排序的指标等。而一个线性模型根据 y 的解释不同(以及设计对应的目标函数)用到回归,分类或排序等场景。 参数指我们需要学习的东西,在线性模型中,参数指我们的线性系数 w。
目标函数:代价 + 正则
模型和参数本身指定了给定输入我们如何做预测,但是没有告诉我们如何去寻找一个比较好的参数,这个时候就需要目标函数登场了。一般的目标函数包含下面两项 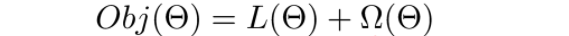 前者称为代价函数,评估模型有多拟合训练数据,又称为经验风险。(对于单条记录,真实值和预测值之间的差异,我们叫做损失函数;对于整个样本,我们称之为代价函数。) 后者称为正则函数,度量模型的复杂度,又称为结构风险。 常见的误差函数有
前者称为代价函数,评估模型有多拟合训练数据,又称为经验风险。(对于单条记录,真实值和预测值之间的差异,我们叫做损失函数;对于整个样本,我们称之为代价函数。) 后者称为正则函数,度量模型的复杂度,又称为结构风险。 常见的误差函数有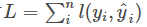 比如平方误差
比如平方误差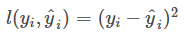 ,logistic 误差函数
,logistic 误差函数 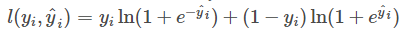 等。而对于线性模型常见的正则化项有 L2 正则和 L1 正则。
等。而对于线性模型常见的正则化项有 L2 正则和 L1 正则。
目标函数就是要最优化经验风险和结构风险。
优化算法
就是给定目标函数之后怎么高效学习的问题。比如 CART 树的分枝和剪枝问题。
Boosted Tree
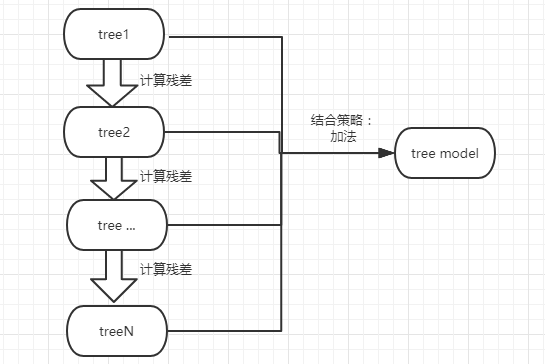 就是不断的生成树的过程,最终将这些树组合成最终的模型。但是后一棵树根节点的数据是真实值与前面所有的树预测的值的差异。 比如要做一个年龄预测的模型,简单起见训练集只有 4 个人 A,B,C,D,树的最大深度为 2。
就是不断的生成树的过程,最终将这些树组合成最终的模型。但是后一棵树根节点的数据是真实值与前面所有的树预测的值的差异。 比如要做一个年龄预测的模型,简单起见训练集只有 4 个人 A,B,C,D,树的最大深度为 2。 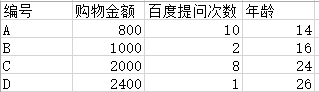
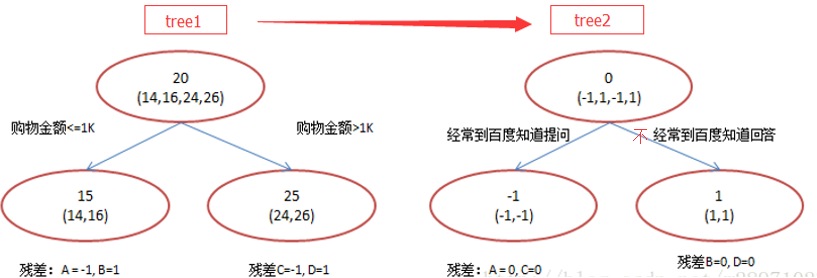
训练后会得到的模型是多棵树,每棵树有若干叶子节点,每个叶子节点对一个分数, 假如来了一个样本,根据这个样本的特征,在每棵树上会落到对应一个叶子节点, 总分数就是把落到的叶子节点的分数加起来,作为预测值。 直观的感受就是  每一轮新的预测,是上次预测值 + 本次学习的函数。
每一轮新的预测,是上次预测值 + 本次学习的函数。
于是对应监督学习的三要素之中的模型和目标函数  上面只是抽象的,那么要实现一个这样的算法,我们要知道: 1、树是什么类型的树?
上面只是抽象的,那么要实现一个这样的算法,我们要知道: 1、树是什么类型的树?
2、怎么生长一棵树?怎么分枝?
3、树什么时候停止生长?
4、确定了一棵树之后,怎么求叶子节点的权重?
Xgboost
传统 GBDT 以 CART 作为基分类器,xgboost 还支持线性分类器,这个时候 xgboost 相当于带 L1 和 L2 正则化项的逻辑回归(分类问题)或者线性回归(回归问题)。本文主要讨论 CART 类型的 xgboost。
CART 采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART 算法生成的决策树是结构简洁的二叉树。它既可以用于分类,也可以用于回归问题。
树的定义: 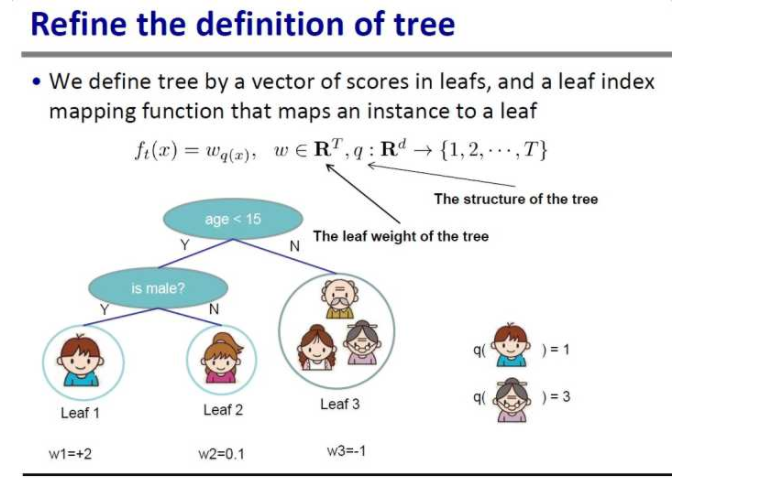
用保存有叶子节点的权重的向量来表示一颗树,叶子节点的索引定义在树结构里面。q 代表树结构,输入一个样本的特征给 q,会落到唯一对应的叶子节点,返回该叶子节点的编号。w 代表叶子权重,输入一个叶子节点编号给 w,返回对应的权重。
树的复杂度的定义: 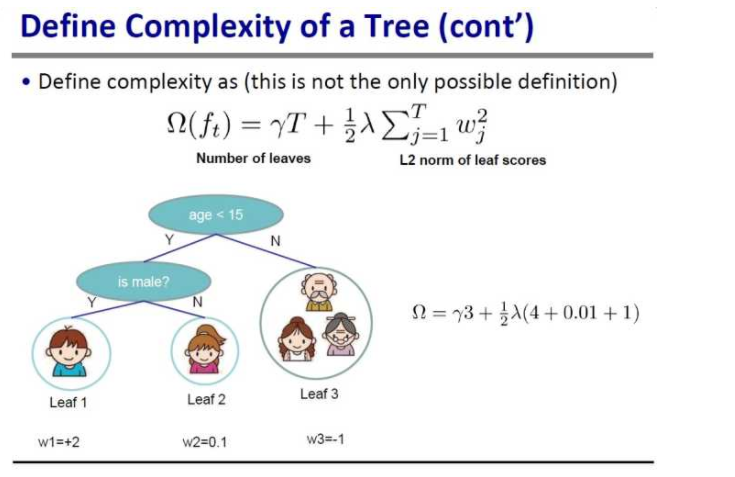 树的复杂度由叶子节点数量以及对应权重的平方和组成。上面这个并不是唯一的树的复杂度定义,只要是满足 L2 范数的表达式都能作为树的复杂度。 到此,就回答了第一个问题——树是什么类型的树。
树的复杂度由叶子节点数量以及对应权重的平方和组成。上面这个并不是唯一的树的复杂度定义,只要是满足 L2 范数的表达式都能作为树的复杂度。 到此,就回答了第一个问题——树是什么类型的树。
然后我们看下第二个问题——树要怎么分裂? 这要从目标函数讲起。 假如穷举所有可能的分裂点(遍历每一个特征和特征值)和分裂方向,我们可以得到 N 课树,每一颗树都能计算出目标函数的值,其中目标函数值最小的树就是我们要的最优树。 但是这样做太慢、太消耗资源。 我们采取贪心算法来生长一棵树,每次找一个最优的特征进行分裂,每个特征是寻找最优点进行分裂,直到到达一定的深度或者不能再分裂(分裂后损失值更大)。
那么什么是最优特征?最优分裂点? 以目标函数值为标准,对比分裂前和分裂后的最小目标函数值。增益(分裂后的代价函数的值减去分裂前的代价函数)最大的点为最优点,对应的特征为最优特征。  具体的做法就是,每一次选特征时,遍历所有特征,求出每个特征对应的最佳分裂点。 把增益最大的特征和分裂点作为下一次特征分裂。
具体的做法就是,每一次选特征时,遍历所有特征,求出每个特征对应的最佳分裂点。 把增益最大的特征和分裂点作为下一次特征分裂。
当分裂之后的增益比分裂之前的增益更小时,或者达到了自定义的树的最大深度时,停止生长。这就是问题三——树什么时候停止生长。 从这也可以看出 xgboost 可以很方便做预剪枝。因为每次都计算分裂前后的增益,当增益小于我们自定义的某个值时,停止分裂。(预剪枝)
问题四——怎么求每棵树的叶子节点的权重? 根据泰勒二级展开近似目标函数  目标函数变形
目标函数变形  其中 I 被定义为每个叶子上面样本集合。可以看到,T 个叶子节点的权重是未知项,其他都是已知的。
其中 I 被定义为每个叶子上面样本集合。可以看到,T 个叶子节点的权重是未知项,其他都是已知的。  要使 Obj 最小,相当于求 Wj 的一元二次方程的最小值问题。
要使 Obj 最小,相当于求 Wj 的一元二次方程的最小值问题。
boosted 算法概述 整个算法的理解如下:
整个算法的理解如下:
a 每次迭代添加一棵树
b 每次迭代前,求出上次预测损失函数一阶导数和二阶导数的函数值
c 根据分裂增益最大化,去生长这棵树
d 把新的树添加到原来模型(新的树可以乘上一个系数,防止过拟合,这个系数就是自己传进来的 eta 参数,学习速率)
单机多线程
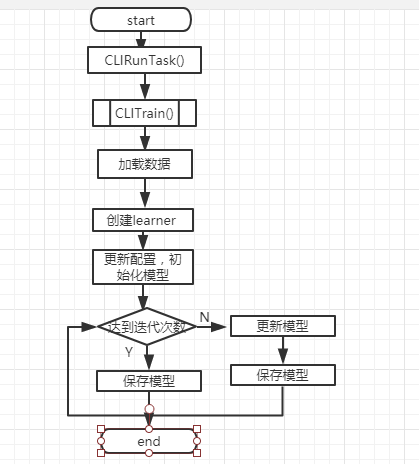
learner->InitModel()、learner->Configure 初始化 Model,确定目标函数和模型,初始化目标函数结构体和模型。模型可以是 gbtree 或 GBLinear 的。
根据模型参数 param.num_round 迭代调用 UpdateOneIter() 来建树。 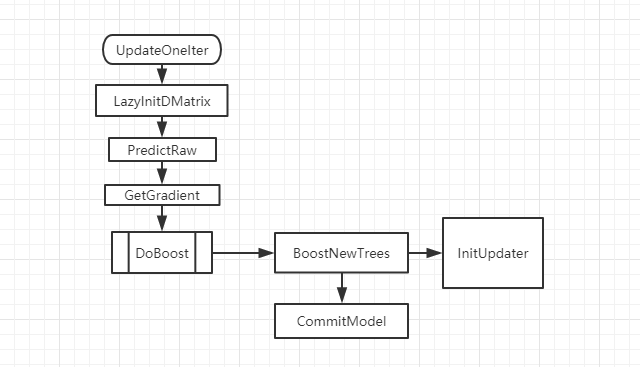 UpdateOneIter 有 4 步,分别是懒加载数据(转为以列为基础的结构),上一步的预测值,目标函数的一阶导数、二阶导数以及 DoBoost 建树。
UpdateOneIter 有 4 步,分别是懒加载数据(转为以列为基础的结构),上一步的预测值,目标函数的一阶导数、二阶导数以及 DoBoost 建树。
其中 DoBoost 又分为 BoostNewTrees(生成多棵树,由参数中的 num_parallel_tree 决定) 和 CommitModel(将多棵树提交到模型,随机森林的思想得到这一次迭代的树)
然后我们看下 BoostNewTrees 生成树的过程。 ColMaker 继承于 TreeUpdater,是单机多线程建树的实现过程。 为了实现多线程定义了三个结构体:ThreadEntry、NodeEntry、Builder。 ThreadEntry 结构体用于多线程中单个线程内的样本统计,一个线程拥有一个 ThreadEntry 变量。
为了实现多线程定义了三个结构体:ThreadEntry、NodeEntry、Builder。 ThreadEntry 结构体用于多线程中单个线程内的样本统计,一个线程拥有一个 ThreadEntry 变量。
NodeEntry 用于一个树节点,所拥有的样本的统计信息。一个节点在分列前,需要将自己的样本分给不同的线程进行处理,最后得到多个 ThreadEntry 变量,汇总到每个节点自己的 NodeEntry 变量中。
多线程使用的是 OpenMP,遍历所有的特征,每个特征一个线程,找到该特征最大增益的分割点,这一部分是并行的。最后通过 SyncBestSolution 来汇总所有线程,找到最优的特征和分割点。直到达到树的最大深度。
在线程内部,会先将数据排序并分块,如果数量较小调用 EnumerateSplit 方法。也就是一个特征只有一个线程。但是它不是遍历每个特征,而是有一个步长,每隔一个步长取一个特征值作为 split point。一个 split point 将样本分为两个子集,然后计算左右子集的增益和权重。选出最优 split point。
如果数据量大则使用 ParallelFindSplit,每一个块对应一个线程。 a 在每个线程里汇总各个线程内分配到的数据样本的统计量 (grad/hess);
b aggregate 所有线程的样本统计 (grad/hess),计算出每个线程分配到的样本集合的边界特征值作为 split point 的最优分割点;
c 在每个线程分配到的样本集合对应的特征值集合进行枚举作为 split point,选出最优分割点;
d 最后通过 SyncBestSolution 来汇总所有线程,找到最优的特征和分割点。
分布式实现
陈天奇博士一开始的目标基本总结下来就是,速度快,可移植,少写代码。
速度快是自然的目标,体现这个目标的一个的想法是在写的似乎机器内部依然沿用单机多线程的优化来减少通信,只在机器之间来进行通信。
可移植性是一个更大的困难,要做分布式机器学习必须有分布式的通信框架。要想要让分布式程序可以运行在不同的环境下比起让一个单机机器学习程序从 linux 移植到 windows 困难许多。但是其实本质上,这个东西和把 linux 移植到 windowss 又没有差别。之所以一个程序可以从 linux 移植到 windows,是因为程序仅仅依赖一些系统调用的接口,而我们只需要在每个平台下面提供一套这类接口就可以了。同样的,根据算法本身的需求,抽象出合理的接口,通过通用的库让平台往接口需求上面去走,就有可能实现一个分布式的通信框架。最后选择了 Allreduce。 MPI_Allreduce 将规约值结果分发到所有进程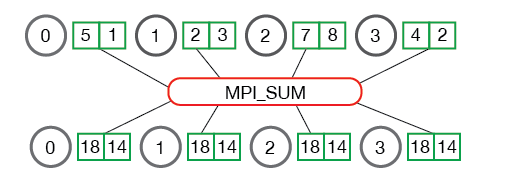 假设有 4 个节点,每个节点有一个长度为 2 的一维数组 a,然后发送一个 sum 求和的指令。它会将所有节点的 a[0] 求和,a[1] 求和,然后发送到所有的节点上,这样所有的节点保存的是同样的东西。
假设有 4 个节点,每个节点有一个长度为 2 的一维数组 a,然后发送一个 sum 求和的指令。它会将所有节点的 a[0] 求和,a[1] 求和,然后发送到所有的节点上,这样所有的节点保存的是同样的东西。
我们将训练集 repartition 为 N 个分区,起 N 个机器,每个机器处理一个分区,对于一个特征来说,每个分区都能找到一个最佳分割点,然后 allreduce 一下,那么每一台机器就会得到其他所有的机器的结果,然后更新自己机器上的模型,这样每台机器上的模型都是一样的。
Rabit(Reliable Allreduce and Broadcast Interface) 是一个可容错的 Allreduce,保留了 Allreduce 和 Broadcast,底层是通过 socket 通讯。说它可容错是因为它为所有的节点设计了一个环状结构,假如某个节点 down 掉了可以通过 ring replication strategy 从相邻的节点恢复。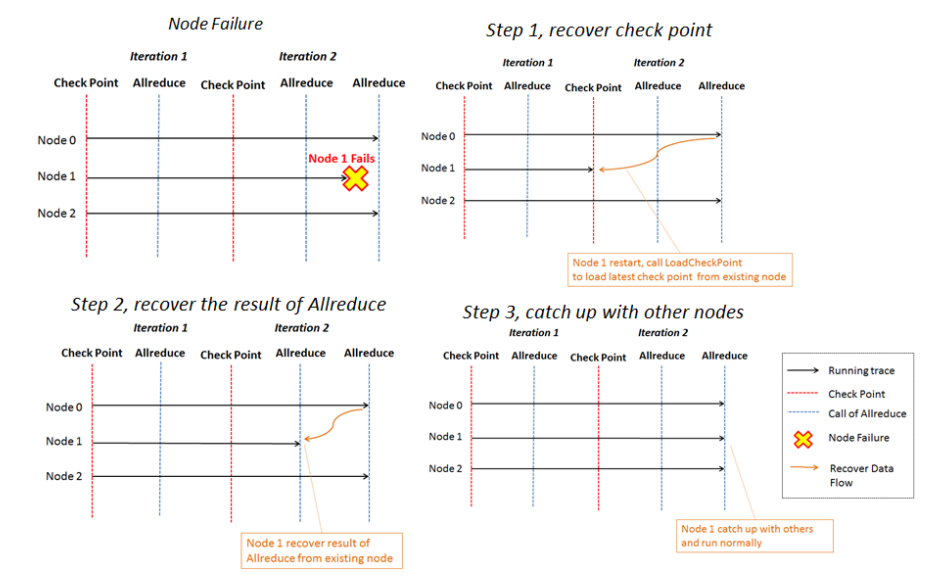 在 yarn 上的实现是
在 yarn 上的实现是 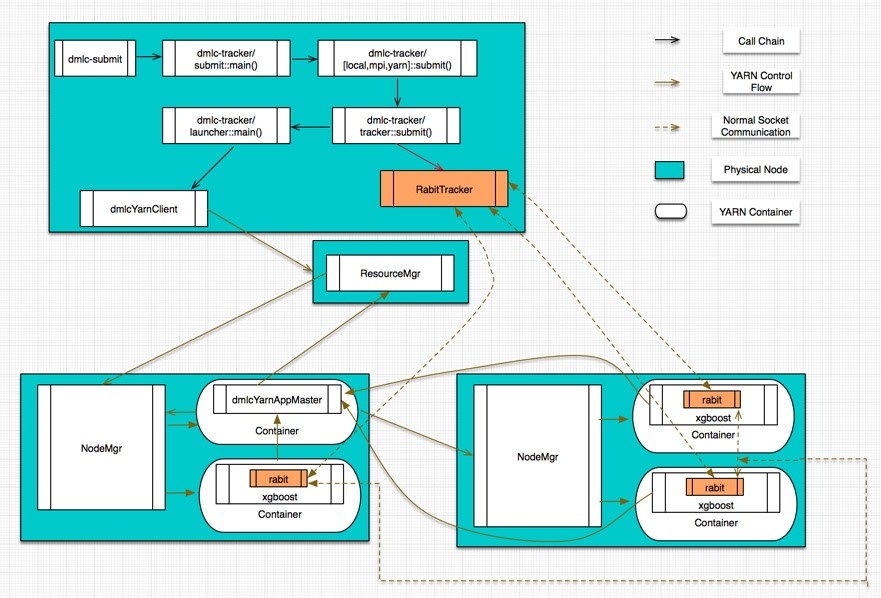
1 当一个 xgboost 任务提交到 yarn 上时,先在 driver 端启动一个 RabitTracker,RabitTracker 提供 N 个 end point 给 worker 连接。
2 然后通过 yarnclient 向 RM 请求资源来创建 AM。
3 RM 先在 NM 上创建一个 container,并在这个 container 里面启动任务的 AM。
4 AM 根据资源配置向 RM 请求具体执行的容器。
5 AM 申请到容器之后,会将 boost 程序发送到容器并启动,同时管理这些容器。
6 每一个 xgboost 通过 rabit 框架和 rabitTracker 通信完成注册,rabitTracker 将这些 rabit 编号并形成环形网络结构。
7 那么 AM 监控和管理容器的运行情况,rabittracker 协调 xgboost 的运作。
RabitTracker 过执行 dmlc-core 工程下的 tracker.py 来创建。具体做得事:
1 启动 daemon 线程,提供 worker 结点注册联接所需的 end point,所有的 worker 结点都可以通过与 Tracker 程序通信来完成自身状态信息的注册。
2 co-ordinate worker 结点的执行:
为 worker 结点分配 Rank 编号。 基于收到的 worker 注册信息完成环形网络结构的构建,并广播给 worker 结点,以确保 worker 结点之间建立起合规的网络拓扑。 当所有的 worker 结点都建立起完备的网络拓扑关系以后,就可以启动计算任务监控整个执行过程。